

Generative A-Eye #1 - 16th Sept,2024
A (more or less) daily newsletter featuring brief summaries of the latest papers related to AI-based human image synthesis, or to research related to this topic.

InstantDrag: Improving Interactivity in Drag-based Image Editing
Drag-based methods have really ramped up in the literature over the last 4-5 months (such as RegionDrag, DragText, FastDrag, InstaDrag, and DragNoise, among others). This one stands out for training on optical flow-centered data. This sub-sector of AI-based human image synthesis research is interesting to anyone who’s ever used zBrush, and to anyone keen to get away from the ambiguities of prompt-based modification, which remains an exercise in serendipity (!).

‘'[An] optimization-free pipeline that enhances interactivity and speed, requiring only an image and a drag instruction as input. InstantDrag consists of two carefully designed networks: a drag-conditioned optical flow generator (FlowGen) and an optical flow-conditioned diffusion model (FlowDiffusion). InstantDrag learns motion dynamics for drag-based image editing in real-world video datasets by decomposing the task into motion generation and motion-conditioned image generation'‘
https://joonghyuk.com/instantdrag-web/
http://export.arxiv.org/abs/2409.08857
Knowledge-Enhanced Facial Expression Recognition with Emotional-to-Neutral Transformation
One of the very few Facial Expression Recognition (FER) papers that appears to make no reference to the Facial Action Coding System (FACS). FACS dominates the literature in expression recognition and generation, and, in my opinion, is holding back this crucial aspect of AI-based human performance. This particular area of human synthesis has a complicated cross-over with psychology and anthropological research, and may be one of the last problems to be solved in AI human representation, in my opinion.

‘Existing facial expression recognition (FER) methods typically fine-tune a pre-trained visual encoder using discrete labels. However, this form of supervision limits to specify the emotional concept of different facial expressions. In this paper, we observe that the rich knowledge in text embeddings, generated by vision-language models, is a promising alternative for learning discriminative facial expression representations. Inspired by this, we propose a novel knowledge-enhanced FER method with an emotional-to-neutral transformation. Specifically, we formulate the FER problem as a process to match the similarity between a facial expression representation and text embeddings.’
http://export.arxiv.org/abs/2409.08598
Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Continuing with FER, we return, inevitably, to FACS, and a novel system that leverages LLMs and LoRAs to identify Action Units (AUs), the base blocks of the (very limited) available expression definitions in FACS.
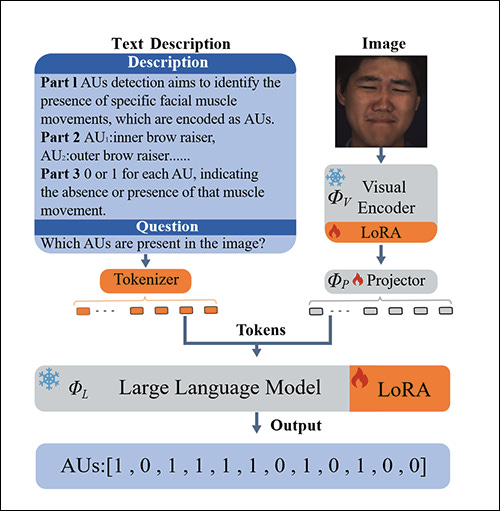
‘Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image.’
http://export.arxiv.org/abs/2409.08444
Risks When Sharing LoRA Fine-Tuned Diffusion Model Weights
The paper’s summary is on the long side, and only excerpted below. However, this is another example of a growing trend in the literature - the extraction of training data images from the latent space of generative models - in this case, in LoRAs that offer customized personalities in systems such as Stable Diffusion and Flux. This is the kind of potential forensic evidence which, in 2024, is having a chilling effect on the generative AI boom, as the largest market contenders realize that training on ad hoc web-scraped collections is a legal minefield in the making.

‘We design and build a variational network autoencoder that takes model weights as input and outputs the reconstruction of private images. To improve the efficiency of training such an autoencoder, we propose a training paradigm with the help of timestep embedding. The results give a surprising answer to this research question: an adversary can generate images containing the same identities as the private images. Furthermore, we demonstrate that no existing defense method, including differential privacy-based methods, can preserve the privacy of private data used for fine-tuning a diffusion model without compromising the utility of a fine-tuned model'‘
http://export.arxiv.org/abs/2409.08482
_________________________
Under the fold
That’s everything that caught my eye in Arxiv for today. I now need to catch up on 10 lost days of Computer Vision output. I should re-emphasize, since this is the first newsletter, that amazing systems and innovations may emerge in the literature, which I will not be covering, if it has no relation to the evolution AI-generated human facial and body synthesis.