Generative A-Eye #10 - 1st Oct,2024
A (more or less) daily newsletter featuring brief summaries of the latest papers related to AI-based human image synthesis, or to research related to this topic.

Arxiv has been having server trouble for a few days. Many of the new papers are not currently available at the main domain, but can be found on the export.arxiv subdomain. Despite over 230 entries today, only DressRecon (see below) really shines, with several other video-centric offerings not providing video materials.
DressRecon: Freeform 4D Human Reconstruction from Monocular Video
Well worth a scroll down the video-laden project page. A formidable-looking GSplat approach to a task that has been handed on through NeRF, GAN, and various other approaches. Handling loose clothing effectively is an ill-posed problem in human synthesis, and one that the fashion computer vision sector is keen to resolve.

'[A] method to reconstruct time-consistent human body models from monocular videos, focusing on extremely loose clothing or handheld object interactions.'
https://jefftan969.github.io/dressrecon/
https://jefftan969.github.io/dressrecon/paper.pdf
Dual Encoder GAN Inversion for High-Fidelity 3D Head Reconstruction from Single Images
Yet another interesting human synthesis paper with a project page so stuffed with videos that it ran for very little time before crashing Chrome. Well, enjoy the brief glimpse of a promising outing, if you can.

‘[A] novel framework built on PanoHead, which excels in synthesizing images from a 360-degree perspective. To achieve realistic 3D modeling of the input image, we introduce a dual encoder system tailored for high-fidelity reconstruction and realistic generation from different viewpoints’
https://berkegokmen1.github.io/dual-enc-3d-gan-inv/
http://export.arxiv.org/abs/2409.20530
Learning to Discover Generalized Facial Expressions
A welcome novel take on expression recognition, which is an under-considered challenge in human image synthesis. Achieves a nearly 10% increase in effectiveness over the SOTA.
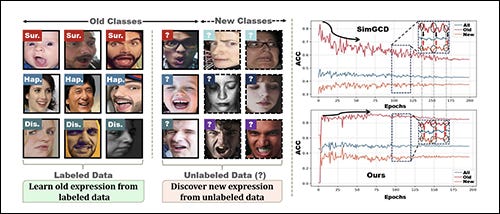
‘We introduce Facial Expression Category Discovery (FECD), a novel task in the domain of open-world facial expression recognition (O-FER). While Generalized Category Discovery (GCD) has been explored in natural image datasets, applying it to facial expressions presents unique challenges. Specifically, we identify two key biases to better understand these challenges: Theoretical Bias-arising from the introduction of new categories in unlabeled training data, and Practical Bias-stemming from the imbalanced and fine-grained nature of facial expression data.’
http://export.arxiv.org/abs/2409.20098
Replace Anyone in Videos
Many projects where video demonstrations are crucial publish the accompanying supplementary much later (if ever), and here we are going to have to take the researchers’ word for the effectiveness of their video inpainting system.

[We] propose the ReplaceAnyone framework, which focuses on localizing and manipulating human motion in videos with diverse and intricate backgrounds. Specifically, we formulate this task as an image-conditioned pose-driven video inpainting paradigm, employing a unified video diffusion architecture that facilitates image-conditioned pose-driven video generation and inpainting within masked video regions.
http://export.arxiv.org/abs/2409.19911
High Quality Human Image Animation using Regional Supervision and Motion Blur Condition
A rare attempt to model motion blur directly into a video diffusion model. Sadly, again, there appear to be no video examples available yet.

‘Although generating reasonable results, existing methods often overlook the need for regional supervision in crucial areas such as the face and hands, and neglect the explicit modeling for motion blur, leading to unrealistic low-quality synthesis. To address these limitations, we first leverage regional supervision for detailed regions to enhance face and hand faithfulness. Second, we model the motion blur explicitly to further improve the appearance quality’
http://export.arxiv.org/abs/2409.19580
Fusion is all you need: Face Fusion for Customized Identity-Preserving Image Synthesis
A project that attempts to embed identity information deeper into the U-Net architecture than your average T2I model, and which claims a new SOTA in similarity metrics, without diverging from the user text prompt.

‘Text-to-image (T2I) models have significantly advanced the development of artificial intelligence, enabling the generation of high-quality images in diverse contexts based on specific text prompts. However, existing T2I-based methods often struggle to accurately reproduce the appearance of individuals from a reference image and to create novel representations of those individuals in various settings. To address this, we leverage the pre-trained UNet from Stable Diffusion to incorporate the target face image directly into the generation process.’
http://export.arxiv.org/abs/2409.19111
My domain expertise is in AI image synthesis, and I’m the former science content head at Metaphysic.ai. I’m an occasional machine learning practitioner, and an educator. I’m also a native Brit, currently resident in Bucharest.
If you want to see more extensive examples of my writing on research, as well as some epic features (many of which hit big at Hacker News and garnered significant traffic), check out my portfolio website at https://martinanderson.ai.