Generative A-Eye #12 - 4th Oct,2024
A (more or less) daily newsletter featuring brief summaries of the latest papers related to AI-based human image synthesis, or to research related to this topic.

I commented on a post from Synthesia on LinkedIn today. The company (there is no identifiable person behind Synthesia’s posts) asked for predictions of the state of generative avatars in 2031.
I replied:
‘I think that limitations around Facial Expression Recognition (FER) – and therefore generation – will make it difficult for avatars to offer a full range of human emotions.
‘This is really a limitation of the state of the art in psychology and anthropology research, whose work feeds into systems like this.
‘Therefore most of the papers I see in the wild, relating to human synthesis, are still relying on the Facial Action Coding System (FACS), which centers around only 6-7 emotional inferences from facial expressions.
‘So if you want smiling avatars, or (for some reason), angry or tearful avatars, it won't be a problem. But for anything more nuanced, the progress we're waiting for is not from the generative AI sector, and I don't think there's much you can do to speed that up.’
I have even stronger feelings about this, and about the inadequacies of FACS; but I have written a lot about this already, so maybe I should save it for the next post on the topic.
The reason I mention it is the first of the selection for today:
Emo3D: Metric and Benchmarking Dataset for 3D Facial Expression Generation from Emotion Description
If there’s anything the human image synthesis sector needs, it’s more and better-annotated data. Here, however, CLIP is used in the workflow, and is likely not up to any task that extends beyond a FACS scope (due to FACS’ extensive influence on annotations that CLIP has ingested).
Nonetheless, the authors offer a new metric, titled Emo3D, and the paper might reward deeper reading.

‘[An] extensive "Text-Image-Expression dataset" spanning a wide spectrum of human emotions, each paired with images and 3D blendshapes. Leveraging Large Language Models (LLMs), we generate a diverse array of textual descriptions, facilitating the capture of a broad spectrum of emotional expressions.’
https://arxiv.org/abs/2410.02049
Social Media Authentication and Combating Deepfakes using Semi-fragile Invisible Image Watermarking
The problem with this paper is that it uses the now-ancient FaceForensics++ dataset as testing material. The world of AI human synthesis has changed so radically since FF++ came out, that the only reason to adhere to it is for like-on-like continuity of comparison with prior papers.
How many years (decades..?) will this incentive undermine the scene?

‘[A] semi-fragile image watermarking technique that embeds an invisible secret message into real images for media authentication. Our proposed watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations and watermark removal attacks. This is facilitated through a unique architecture of our proposed technique consisting of critic and adversarial networks that enforce high image quality and resiliency to watermark removal efforts, respectively, along with the backbone encoder-decoder and the discriminator networks.’
https://arxiv.org/abs/2410.01906
EgoAvatar: Egocentric View-Driven and Photorealistic Full-body Avatars
EDIT: It turns out that the PDF version of this paper does have a project page link, but it looks like the rest of the text, so that you would not guess that there is a hyperlink; and it was not shown as a link in the HTML abstract either.
This was pointed out to me by Marc Habermann, one of the paper’s authors, in an email. He has said that the authors will publish a new version where the link is clearer.
The project page is at: https://vcai.mpi-inf.mpg.de/projects/EgoAvatar/
The only reason to publish a knock-em-dead avatar system on a Friday is a) that there is no supplementary material yet, or b) the qualitative results suck so much that the minimum obligation to get the paper out the door is being met while the world heads to its weekend.
In this case, where the authors (including Google) are proposing a 3DGS avatar system aimed at telepresence, there’s no way of knowing unless a YouTube video and/or a project site emerges later.
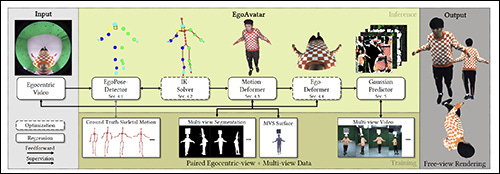
‘[We], for the first time in literature, propose a person-specific egocentric telepresence approach, which jointly models the photoreal digital avatar while also driving it from a single egocentric video. We first present a character model that is animatible, i.e. can be solely driven by skeletal motion, while being capable of modeling geometry and appearance.
‘Then, we introduce a personalized egocentric motion capture component, which recovers full-body motion from an egocentric video. Finally, we apply the recovered pose to our character model and perform a test-time mesh refinement such that the geometry faithfully projects onto the egocentric view.’
https://arxiv.org/abs/2410.01835
Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models
For me this is a ‘wow’ paper, though it’s so niche to Stable Diffusion practitioners that I am undecided whether to write it up.
Basically, the authors have developed an alternative to Classifier-Free Guidance (CFG) in a diffusion system. A higher CFG value forces the system to be more accurate to your prompt, but at the cost of image quality.
Here, a new system, titled Adaptive Projected Guidance (APG) allows a user to increase prompt-accuracy without degrading the generated result nearly so much.

‘Classifier-free guidance (CFG) is crucial for improving both generation quality and alignment between the input condition and final output in diffusion models. While a high guidance scale is generally required to enhance these aspects, it also causes oversaturation and unrealistic artifacts. In this paper, we revisit the CFG update rule and introduce modifications to address this issue.
‘We first decompose the update term in CFG into parallel and orthogonal components with respect to the conditional model prediction and observe that the parallel component primarily causes oversaturation, while the orthogonal component enhances image quality. Accordingly, we propose down-weighting the parallel component to achieve high-quality generations without oversaturation.
‘Additionally, we draw a connection between CFG and gradient ascent and introduce a new rescaling and momentum method for the CFG update rule based on this insight. Our approach, termed adaptive projected guidance (APG), retains the quality-boosting advantages of CFG while enabling the use of higher guidance scales without oversaturation.' …
'Through extensive experiments, we showed that APG improves FID, recall, and saturation metrics compared to CFG, while maintaining similar or better precision. Thus, APG offers a plug-and-play alternative to standard CFG capable of delivering superior results with practically no additional computational overhead. Like CFG, challenges remain in accelerating APG so that the sampling cost approaches.’
https://arxiv.org/abs/2410.02416
My domain expertise is in AI image synthesis, and I’m the former science content head at Metaphysic.ai. I’m an occasional machine learning practitioner, and an educator. I’m also a native Brit, currently resident in Bucharest.
If you want to see more extensive examples of my writing on research, as well as some epic features (many of which hit big at Hacker News and garnered significant traffic), check out my portfolio website at https://martinanderson.ai.