Generative A-Eye #3 - 18th Sept,2024
A (more or less) daily newsletter featuring brief summaries of the latest papers related to AI-based human image synthesis, or to research related to this topic.

I’ve been a proponent of Gaussian Splatting as a potential replacement for autoencoder-based facial synthesis (i.e., the 2017-era deepfake code that led to DeepFaceLive et al.), most especially since the advent of GaussianAvatar and Animatable Gaussian Splats (ASH) last December (my commentary on the latter extended to Hacker News).
(The cross-enactment video below is from the GaussianAvatar project. If you’re reading this in a newsletter, clicking on it will take you to SubStack, where you can play the video)
I was interested today to read the opinion of GSplat’s potential from one of the few people at LinkedIn that are posting movie-style experiments with the technology - design professional Oliver Pavicevic.
In a reply comment to his own posted Star Wars-inspired Splat video, Pavicevic says:
‘[Most] of the tests that I'm doing are targeted at understanding if Gaussian Splatting is a viable option for VFX work. From that standpoint, I still don't have any final conclusion, as it has many drawbacks. And I'm not sure if it can go from a 6 rating to 11. Probably it can't. But I'm pretty surprised, because I didn't think that it would go from 3 to 6 or 7.
I think that with smart camera movement […] it can be used with a lot of success for lower budget projects. Not a Hollywood movie. But it can find a place in field of marketing commercials, or music videos where a cost/time are a big concern.’
In the computer vision literature this year, the emphasis on GSplat has moved from the astonishing deepfake-style projects to environmental contexts, to SLAM, synthetic data generation, and has generally diverted away from human synthesis.
Of course, something interesting in this line could be cooking at a major VFX company’s research division. Given the December 2023 releases, it seems hard to believe that GSplat will be relegated to NeRF status - not least because GSplat uses explicit 3D coordinates, just like CGI, whereas nearly all other neural rendering methods (such as NeRF) require complex coordinate interpretation through secondary systems.
Today’s papers that caught my eye:
OmniGen: Unified Image Generation
This is either HUGE or, if the code and weights never come, just another ring-fenced API mystery. OmniGen is a bold new generative Latent Diffusion Model from the Beijing Academy of Artificial Intelligence that rethinks and simplifies the architecture of approaches such as Stable Diffusion - and claims that ancillary systems such as ControlNet are not needed. It supports multi-modal input, and was trained on a curated dataset called X2I (‘Anything to image’). X2I draws on diverse other datasets, including Stable Diffusion’s own LAION-Aesthetic curation. Since LAION is an ad hoc web-scraped dataset, that puts OmniGen on shaky legal ground in the Occident.
Natively, OmniGen can perform tasks such as subject-driven image generation, deblurring, pose detection, and depth-image generation, without adjunct technologies (see this page for details).

‘Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGen is characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities.’
http://export.arxiv.org/abs/2409.11340
https://github.com/VectorSpaceLab/OmniGen
SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
Full-body Gaussian splatting is less interesting to me than face-based GSplat - but much more interesting to the fashion industry, for instance. This outing, from ETH Zürich, Meta, and Balgrist University Hospital ‘regularizes splat features by modeling them as the outputs of a corresponding implicit neural field’. As far as I can tell at a casual glance at the paper, this removes or impairs the XYZ coordinate transparency that makes GSplat appealing, in favor of superior recreation to prior approaches (see image below).

‘[We] identify the lack of spatial autocorrelation of splat features as one of the factors contributing to the suboptimal performance of the 3DGS technique in sparse reconstruction settings. To address the issue, we propose an optimization strategy that effectively regularizes splat features by modeling them as the outputs of a corresponding implicit neural field. This results in a consistent enhancement of reconstruction quality across various scenarios’
http://export.arxiv.org/abs/2409.11211
https://markomih.github.io/SplatFields/
Shaking the Fake: Detecting Deepfake Videos in Real Time via Active Probes
This is cool and, in theory, effective. The system verifies your face by sending a ‘shake’ command to your phone. Typical autoencoder deepfake systems are very bad at motion blur, and will produce unrealistically crisp overlaid content at the moment of the shake, revealing the fraud. After a summer of mediocre deepfake-detection papers, this is at least a refreshing take on the problem.
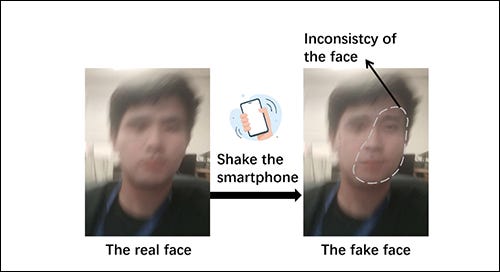
‘[A] new real-time deepfake detection method that innovatively exploits deepfake models' inability to adapt to physical interference. Specifically, SFake actively sends probes to trigger mechanical vibrations on the smartphone, resulting in the controllable feature on the footage. Consequently, SFake determines whether the face is swapped by deepfake based on the consistency of the facial area with the probe pattern’
http://export.arxiv.org/abs/2409.10889
Other papers of interest today:
MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance
https://github.com/Open-Debin/MM2Latent
http://export.arxiv.org/abs/2409.11010
_________________________
My domain expertise is in AI image synthesis, and I’m the former science content head at Metaphysic.ai. I’m an AI developer, current machine learning practitioner, and an educator. I’m also a native Brit, currently resident in Bucharest, but possibly interested in relocation.
If you want to see more extensive examples of my writing on research, as well as some epic features, many of which hit big at Hacker News and garnered significant traffic, check out my portfolio website at https://martinanderson.ai.