Speeding Up Traditional CGI Render Schedules With A Convolutional Neural Network
Monte Carlo rendering at just a fraction of the horrendous computation times.

Can a systematic and dedicated system, newly revealed by Intel, be a better solution for speeding up high quality CGI renders Gigapixel’s sporadic results?
As someone who used to leave Cinema 4D running for days at a time on particularly complex image or video renders, it came as no surprise to me that CGI professionals and enthusiasts would welcome the possibility of creating smaller renders that could be convincingly upsampled afterwards by faster machine learning super-resolution algorithms - for instance, by Topaz’s black-box proprietary offerings, or by rendering low fps video and using DAIN or RIFE to interpolate frames, cutting down on render times.
Indeed, Gigapixel has acknowledged this trend in usage of its products recently, with a dedicated ‘Art & CG’ trained model:
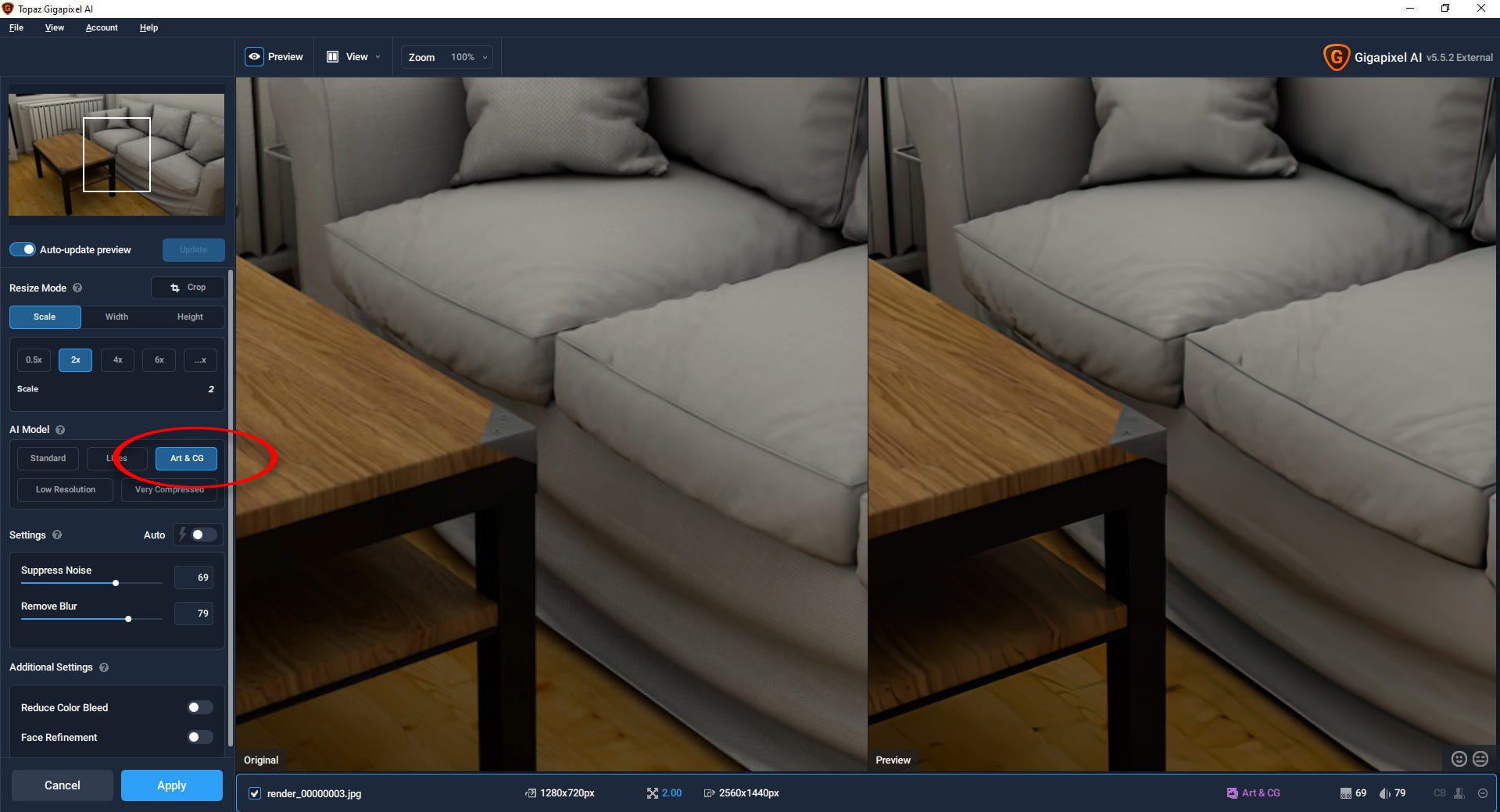
But, as ever with super-resolution, the potential for coherent and consistent upscaling is hobbled by the generic traits of the training data, and there is no way to train your own. A dedicated framework is indicated.
A New Speed Record For Monte Carlo
So, a new collaboration between Portland State University and Intel offers a halfway-house between the prospect of neural rendering and NeRF making traditional CGI obsolete (which is years away), and traditional mesh rendering, which is currently sticking its head in the sand to drown out the distant drums of machine learning.
If you’re not a CGI hobbyist yourself, you won’t know the hunger for better hardware that comes when you turn away from the Quasi-Monte Carlo (QMC) rendering solution in your 3D application’s GUI (an approximated implementation, since pure Monte Carlo is not even an option in C4D due to the extraordinary render times it would produce).
Monte Carlo brutally and randomly calculates every possible light path through the scene, without any of the sampling optimizations of standard global illumination/radiosity techniques.
The new paper, entitled Fast Monte Carlo Rendering via Multi-Resolution Sampling, itself illustrates the related waiting times for this method well, even with the typo:

Source: https://arxiv.org/pdf/2106.12802.pdf
That’s 20 minutes for one frame, of a single object on a basic depth-mapped background, with varying opacity textures, on a card with 12 GB of GDDR5X memory operating on Blender content at an effective memory bandwidth of 547.58 GB/s.
It’s like sending your grandpa to map Alaska on a bike, with a pencil and paper. Bless him, he will do it eventually.
The Intel technique, developed in association with Portland State University, instead quickly renders the scene twice: once at a low resolution with high samplerate (LRHS), and then again at a high resolution with a low samplerate (HRLS).

Each render has half of what’s needed for high quality output, and until now, the only way to combine these characteristics has been to turn the dial up to 11, hit render, and bake (and eat) a turkey.
The two unsatisfactory renders are then passed through a convolutional neural network trained on high quality renders, to produce a new HQ image that welds the opposing characteristics together, comfortably improving on the cruder denoising algorithms incorporated into most implementations of MC/QMC.

Source: https://github.com/hqqxyy/msspl
The contributing ‘Blender Cycles Ray-tracing (BCR)’ dataset on which the algorithm is trained has been compiled by the researchers, and contains 2449 high quality images rendered across 1463 models at a variety of sampling rates from 1-8 up to 4000 spp, each at 1080p resolution.
Each image also contains 33 layers for albedo, normal, diffuse, glossy, and other typical separations in a master render.

Source: https://github.com/hqqxyy/msspl/blob/main/figures/layers.png
The dataset will be released soon, according to the paper.

The researchers compared the results against standard resizing approaches, as well as super-resolution methods of recent years, and demonstrated promising results.


Though currently the best in class, the results of the Intel/Portland research are not perfect. But the real promise lies in the provision of a potential framework that can train dedicated models based on limited hi-res renders that are contextual to a project’s own data - and then use quick, lower-quality renders to obtain a greater rendering fidelity than with a ‘generic CGI’ dataset.
In many similar cases, model training times might obviate the usefulness of such a system. In the case of Monte Carlo, they could offer a massive improvement.